
Web Server & Application Server解惑
Web Server & Application Server解惑
参考文章与书籍
如果你使用Java或Ruby开发过Web项目,你一定了解过Tomcat和Puma,他们本质上都是一种容器,具有监听端口,返回文件或动态内容的服务。但这样的表述有点儿抽象,SpringBoot 和 Rails 为什么不自己去做所有的事儿?而是需要在内部嵌入这么个玩意儿。我们从历史进程中一点点看。
Web服务器的历史
版本1
最初Web服务(Web Server)是一个很简单的玩意儿,在端口上监听,解析HTTP请求,把请求对应的文件返回。
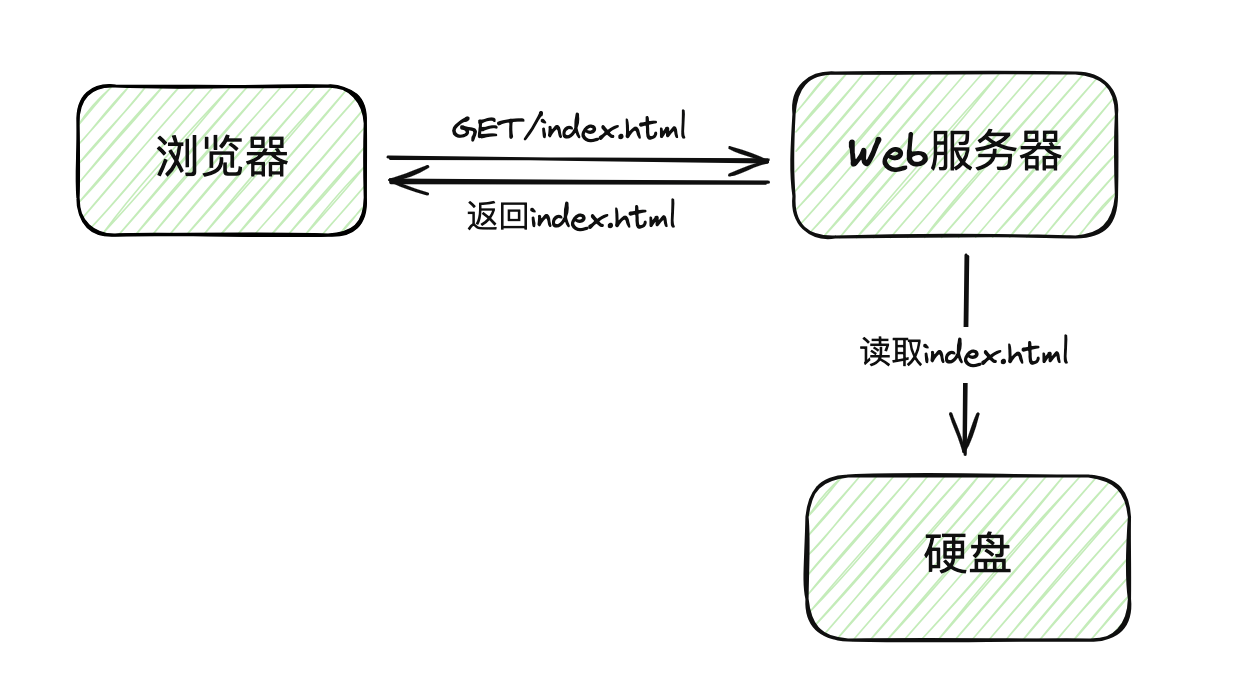
实际上只要了解socket编程与HTTP网络协议,就能很简单的制作出一个玩具Web服务器。参考这篇文章:构建你自己的Web服务器。
版本2
很常见的一个需求,鉴权操作。我需要通过解析请求,知道对方是谁,并从数据库中查询一下对方是否有权限,我们称为应用服务(Application Server)。
但是版本1中的服务不支持这种操作,那我们就再写一个服务(另一个进程中),专门用于数据库查询并校验身份。当请求来时,先到Web服务中,Web服务再去问应用服务,看看能操作不,等收到结果后进行返回。两个服务职责也被很好的分离开了。
但是这两个服务该怎么通信呢?一种办法是对于每个动态请求,Web服务都创建一个应用服务的子进程,通过环境变量将信息进行传递,子进程通过读取环境变量知道要查谁。而子进程查询判断完后,可以知道浏览器与Web服务建立的socket fd,通过标准输出重定向到该fd中,直接就能给用户返回了。这也就是大名鼎鼎的CGI了。
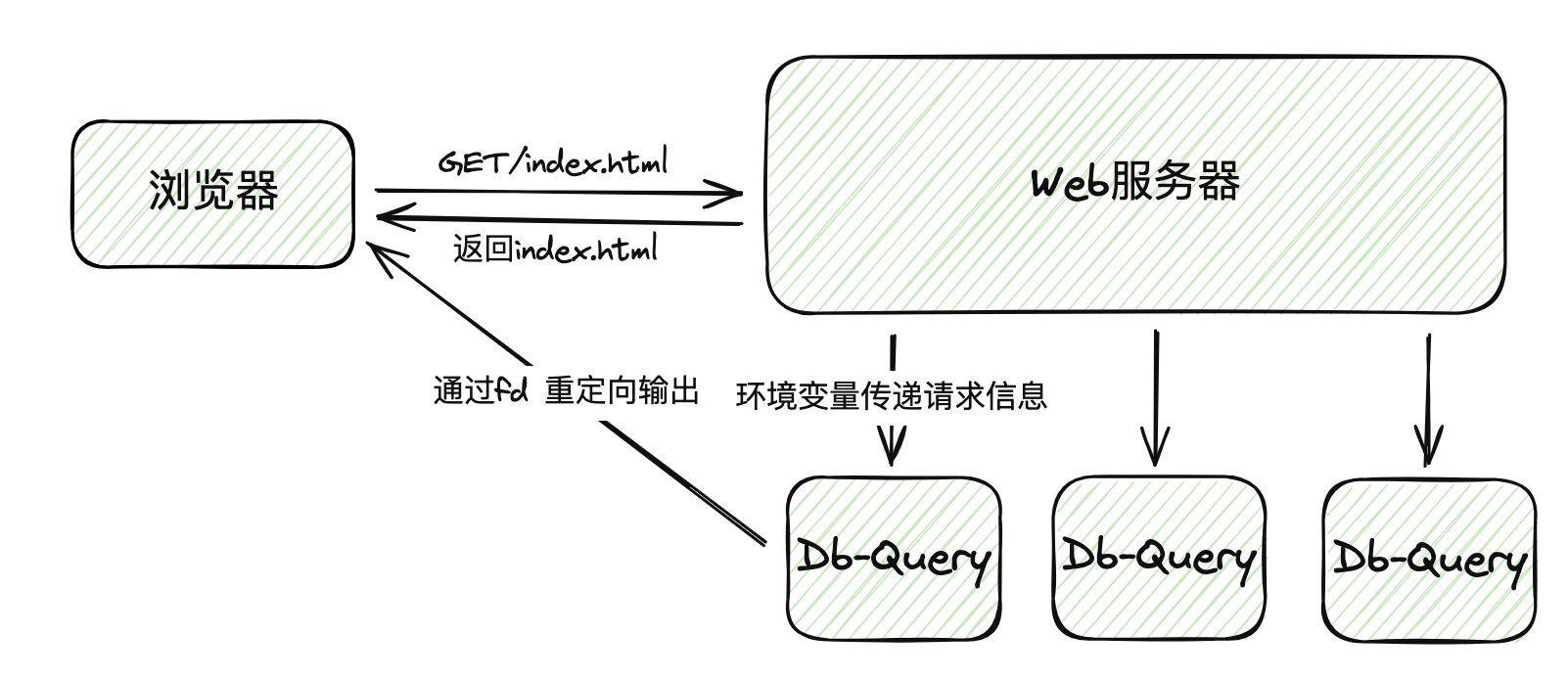
但这样看的话,进程的频繁创建和销毁可是很消耗资源的。而且开发者需要自己操作环境变量,也需要在程序中输出HTML,就很麻烦啊。
版本3
现在程序员关注的点就是获取请求信息,执行业务逻辑,输出响应。其他的环境变量,重定向什么的就别烦我们了。
那这就好办了,程序员自己创建一个类,写具体的业务逻辑,我们创建一个HttpRequest对象,一个HttpResponse对象传递给这个类以供使用。那这就和我们最初使用的Servlet很像了,而负责创建这俩对象的任务就交给了Tomcat。Servlet本质上是一种规范或接口。
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class HelloWorldServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 设置响应内容类型为文本/纯文本
response.setContentType("text/plain");
response.setCharacterEncoding("UTF-8");
// 输出响应正文
PrintWriter out = response.getWriter();
out.println("Hello, World! This is a simple Servlet example.");
// 关闭输出流
out.close();
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// ...
}
}那比如说我要返回一段html,其中这段html中很多内容是动态的,总不能一行一行写到代码里吧。
那Tomcat也有办法,在HTML中混杂代码,这就是JSP!!!😂在执行期会被编译为Servlet。这样就很方便了。
其实类似的,Ruby中的Rack和Python中的WSGI,都是使用了类似的思想。如果原理清楚了,那学另外两个就很容易了。
问题思考
为什么SpringBoot不自己处理请求,而是交给Tomcat
Rails也是一样的,为什么不自己处理请求,而是交给Puma
从上面的历史讲解中就能看到,这就是专注点分离。
就好比你开了一家餐厅,雇佣的厨师长是一位做菜很棒的大厨,而你一定不会让厨师长既要做菜,又要去前台要订单,等做好菜,再端过去吧。一定是有专门的前台 和 后厨进行配合工作。那再回到程序中,Tomcat就是那个传送订单的,Servlet就是那个做菜的(SpringMVC本质上是使用的Servlet)。
当然还有一个很关键的一点,你可以更换前台和后厨!!!比如现在很流行Undertow,我们能很方便的把Tomcat替换为Undertow,这就是因为Undertow也实现了Servlet协议接口,能保证Servlet本身不变的同时,替换掉处理请求的主体,性能被更好的优化。而在Ruby中就更不用说了,前台,后厨都有大量的备选方案。
Application Server vs Web Server (Nginx & Apache)
Nginx是目前很主流的Web服务器,比如反向代理,静态资源读取等。本质上就是我们阶段一中所说的。但是它和Tomcat这种应用服务器有什么区别? 为什么Nginx能做到并发量那么高?
Nginx、Puma 和 Tomcat 都可以作为 Web 服务器,但它们的设计哲学、工作模式和对资源的利用方式有所不同,导致它们在处理高并发请求时表现出不同的性能特点。其中最本质的就是职责不同,请求模型不同。
请求模型不同:
Nginx 最显著的优势在于其采用了高效的事件驱动架构和异步非阻塞I/O模型。这种模型允许Nginx在一个工作进程中同时处理数千甚至数万个并发连接,而不会因为等待某个操作(如磁盘I/O或网络通信)完成而阻塞其他请求的处理。
而应用服务器比如Tomcat,Puma 采用多线程模型,每个线程可以独立处理一个请求。虽然线程比进程更轻量级,但线程间共享内存空间可能导致资源竞争和锁的使用,特别是在高并发场景下可能会引入额外的同步开销。另外,如果某个线程执行的业务逻辑耗时较长,可能会阻塞其他线程的执行,影响整体并发能力。
职责不同:
Nginx 在处理静态资源请求时非常高效,因为它只需直接读取文件并将其发送回客户端,无需进行复杂的计算或脚本解释。对于动态请求,Nginx 通常作为反向代理,将请求转发给后端应用服务器(如Puma、Tomcat等)处理,自身并不直接执行业务逻辑。
Puma 和 Tomcat 在处理动态请求时需要执行复杂的业务逻辑、脚本解释、数据库查询等工作,这些操作往往比单纯返回静态文件更耗时且资源消耗更大。特别是对于Tomcat,由于其运行在JVM之上,Java应用程序在内存管理和垃圾回收(GC)方面的特性可能在高并发下导致性能波动,如频繁的GC暂停可能会暂时降低系统的响应速度。
Application Server 和 Web Server的区别
现在两者的概念很容易混淆,主要是因为有些功能是重合的。比如静态文件读取返回,Application Server也能做到。
但实际中两种往往结合使用,就比如通过Nginx读取静态资源,对于复杂操作反向代理的Tomcat或者Puma中。
Application Server 更侧重于业务实现
Web Server 更侧重于端口监听,资源读取,路由转发等
